Intelligent Dynamically Reconfigurable Computing
This direction of research in CASL mainly revolves around developing an intelligent dynamically reconfigurable computation platform that provides maximum performance for distinct programs and algorithms with diverse requirements. For several years, general-purpose processors were optimized for the common case and were still able to provide reasonable performance for a wide range of applications. Today, diverse applications with distinct requirements are quickly being developed that cannot reach their maximum performance on a single hardware platform. Even new generations of the same algorithm may require a new set of characteristics in the hardware. Domain-specific architectures (DSAs) that rather than using hardware resources to support programmability, focus on implementing operations that a certain application needs, can help applications scale their performance. However, as applications become more diverse and evolve quickly, designing static DSAs will no longer be a practical solution for two reasons: (i) The process for such designs is costly, requires expertise across several domains, and is slow and therefore cannot keep up with the fast pace of algorithm development; and (ii) A system of several fixed specialized hardware platforms is not a scalable solution. To make specialized hardware a practical solution, we are developing an intelligent dynamically reconfigurable computation to be substituted with the current general-purpose processors and conventional static DSAs, in which to simultaneously execute distinct programs, hardware is reconfigured, thus, each program reaches its peak performance without sacrificing its performance for the common case. To achieve our goal, we conduct interdisciplinary research to answer three key questions:
How to determine an ideal configuration?
We accelerate the process of determining the ideal hardware configuration for target programs with particular specifications, through a combination of optimizations and machine learning (ML) techniques. After manually studying the optimized configurations for multiple programs to be executed on a single hardware, we use modern techniques such as ML models for developing intelligent dynamic reconfiguration, in which the platform gradually learns the requirements for new algorithms and reconfigures itself to execute them faster and more efficiently.
How to reconfigure?
We explore the execution models for dynamic hardware reconfigurability. The execution models for general-purpose processors have been the instruction-driven model that aligns their goal of programmability. In a reconfigurable DSA, however, since hardware and software are unified components integrated with data, a data-driven execution model or alternative models are potentially more beneficial.
What to reconfigure?
While our short-term goal is to prototype the main idea of reconfigurable FPGAs as a proof of concept, in the long term, we aim to integrate our computation scheme with emerging technologies to take advantage of those characteristics that align with efficient dynamic reconfigurability.
Sparse Problem Acceleration
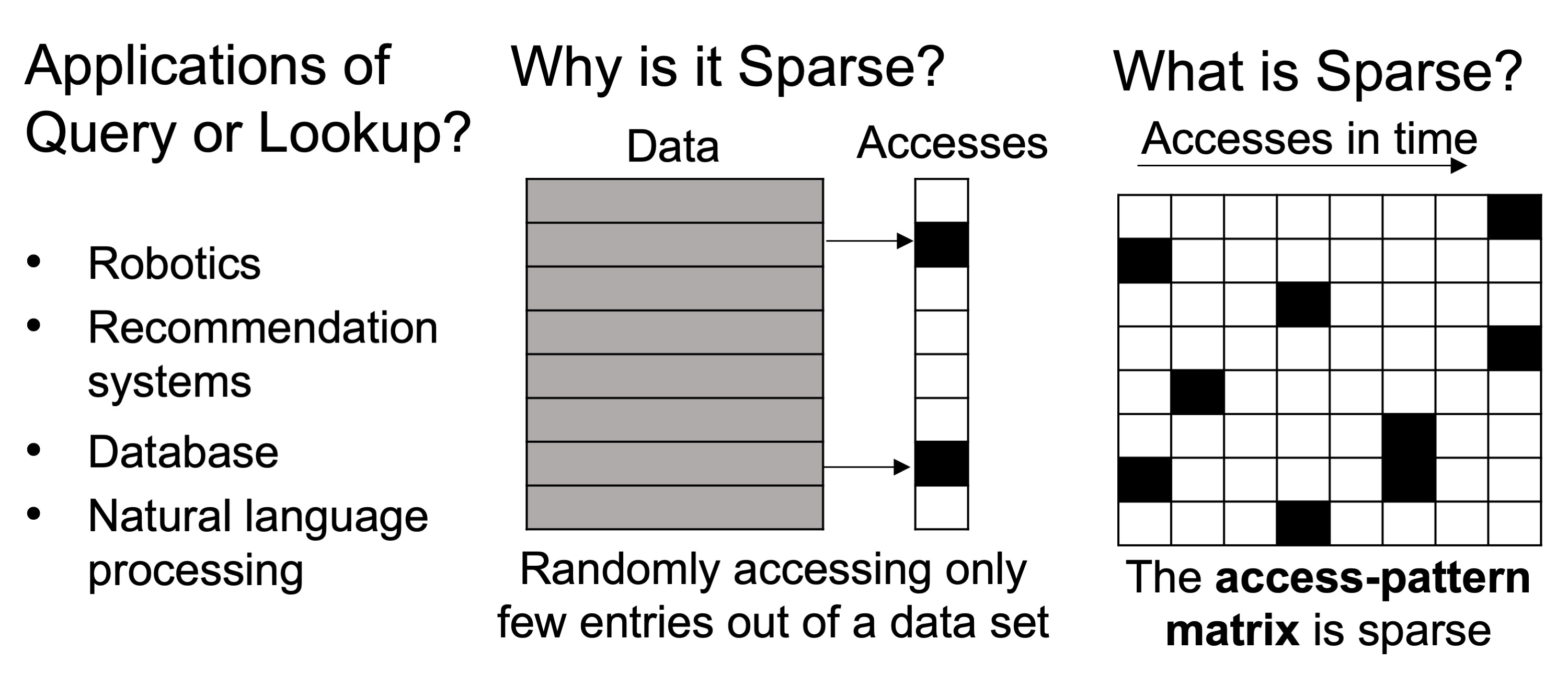
In CASL, we also explore accelerating sparse problems because it is not just the type of computations that defines the characteristics of hardware, data does too. In fact, in almost all application domains in the real world from scientific computing, to robotics and machine learning, data is sparse. Therefore, sparse dominates and we design for sparse. The first category of sparse problems that we talk about here is a query or lookup with applications in domains such as robotics and recommendation systems. In this category of sparse problems, we have a data set that randomly gets accessed. Therefore, in this category, data itself is dense, but the pattern of memory access is sparse. While our short-term goal is to prototype the main idea of reconfigurable FPGAs as a proof of concept, in the long term, we aim to integrate our computation scheme with emerging technologies to take advantage of those characteristics that align with efficient dynamic reconfigurability.
Reducing irregular memory accesses in robotics algorithms
The first and the most popular challenge of sparse problems is irregular and inefficient memory accesses. In robotics, for instance, as a robot moves and observes various objects in the environment, it requires accessing/updating data corresponding to observed objects that are randomly scattered in memory. Such irregular random memory accesses challenge the time-sensitive tasks that a robot does, such as simultaneous localization and mapping (SLAM). Besides, in robotics, energy resources are limited. Thus, performing a critical task such as SLAM by carrying out several power-hungry memory accesses is not a clever and efficient way to utilize limited power resources. An example of our solutions to deal with this challenge is a power-aware implementation of SLAM by customizing efficient sparse algebra (Pisces), which exploits sparsity, the key characteristic of SLAM missed in prior work, in co-optimizing power consumption and latency. Pisces transforms the sparse matrix algebra to a sequence of fixed-size dense matrix algebra and implements them in a pipelined computation engine, which reads the operands from on-chip memory only once and performs all required operations on intermediate data before writing them back to the memory. Therefore, Pisces consumes 2.5x less power and executes SLAM 7.4x faster than the state of the art.
Dealing with sparsity challenges in recommendation systems
Irregular random memory accesses are also an obstacle in large-scale applications, such as recommendation systems, that not only are widely used in industry for e-commerce and entertainment but also have broader applications in domains such as e-learning and healthcare. To reduce the amount of data movement and thereby better utilize memory bandwidth, we can potentially use near-data processing (NDP) solutions for recommendation systems. The issue of using NDP, however, is that it relies on spatial locality, an optimistic but not realistic assumption.
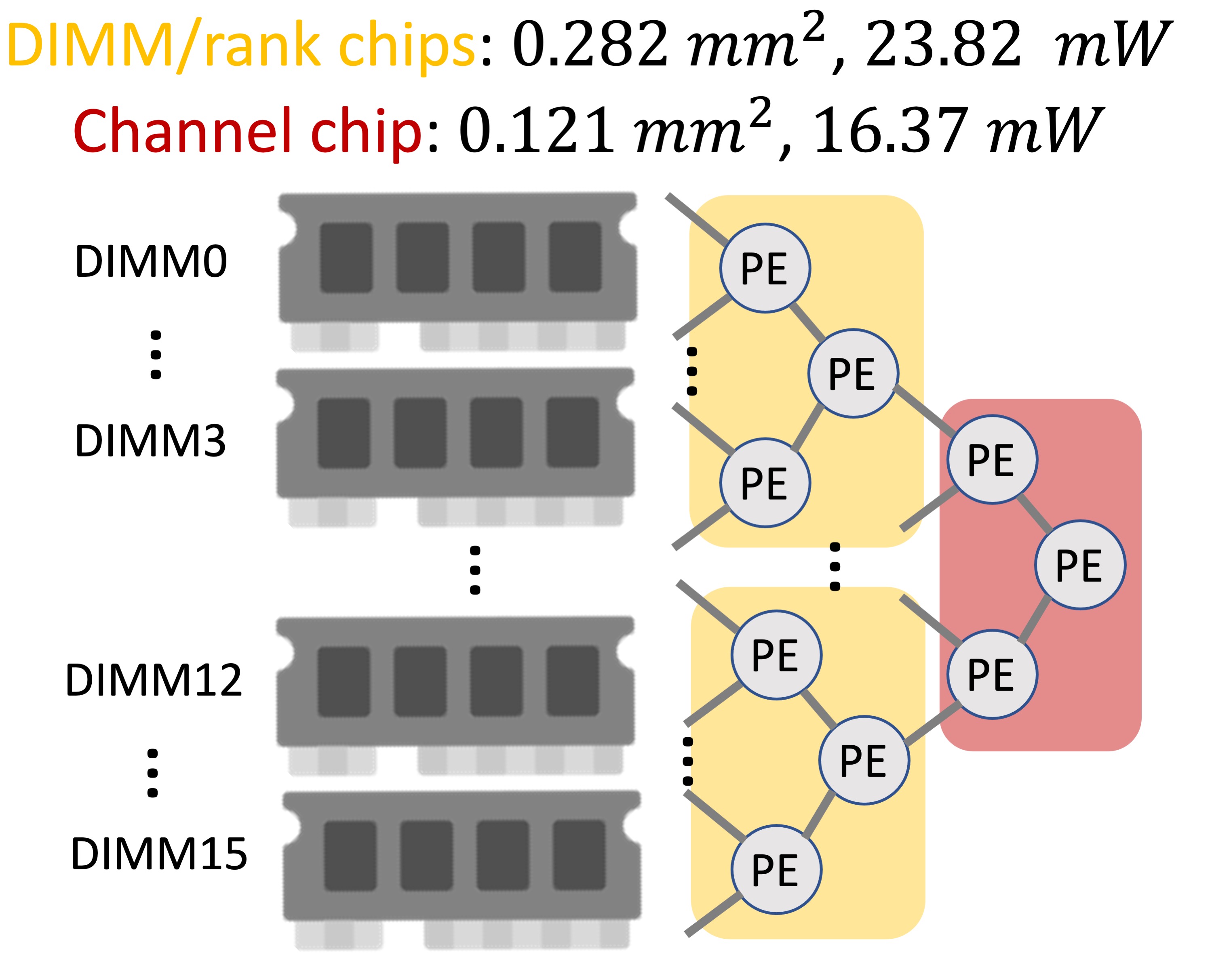
A solution that we proposed to deal with random memory accesses in recommendation systems is an efficient near-memory intelligent reduction tree (Fafnir) each leaf of which is connected to a memory unit (e.g., DRAM rank) in a memory system, and the nodes gradually apply reduction operations while data is gathered from any memory unit. Fafnir does not rely on spatial locality; therefore, it minimizes data movement by performing entire operations at NDP and fully benefits from parallel memory accesses. We implement Fafnir on an FPGA and in 7nm ASAP ASIC. Our evaluation shows that Fafnir executes recommendation systems 21.3x more quickly than the state-of-the-art NDP proposal.
Minimizing the negative impact of data dependencies in scientific computing
Solving partial differential equations (PDEs) is a key component in scientific computing, another example of sparse problems. PDEs are used for modeling physical phenomena in several domains from biology to chemical science. To model a physical phenomenon using PDEs and solve them using digital computers, the first step is to discretize it into a grid and represent them as a system of linear equations. Discretization, however, does not occupy all the points in a 3D grid. As a result, the coefficient matrix, used for representing the PDEs as a system of linear equations, is sparse.

The unsolved challenge in solving PDEs is data dependency, which limits utilizing the available memory bandwidth. To minimize the negative impact of data dependencies on performance, we proposed a lightweight reconfigurable sparse-computation accelerator (Alrescha), the key insight of which is to convert the mathematical dependencies to gate-level dependencies to reduce the critical-path latency. As a result, even dependent instructions can be executed mostly in parallel. Based on this insight, Alrescha breaks down a sparse problem into a majority of parallel and a minority of small data-dependent instructions that can be executed quickly (in fewer cycles) in hardware. Alrescha executes sparse scientific computing, including solving partial differential equations, 15.6x faster than GPUs. Moreover, compared to GPUs, Alrescha consumes 14x less energy. Another example of such dependencies is in matrix inversion, for efficiently executing which, we proposed matrix inversion acceleration near memory (Maia).
Characterizing the performance implications of compression in sparse problems
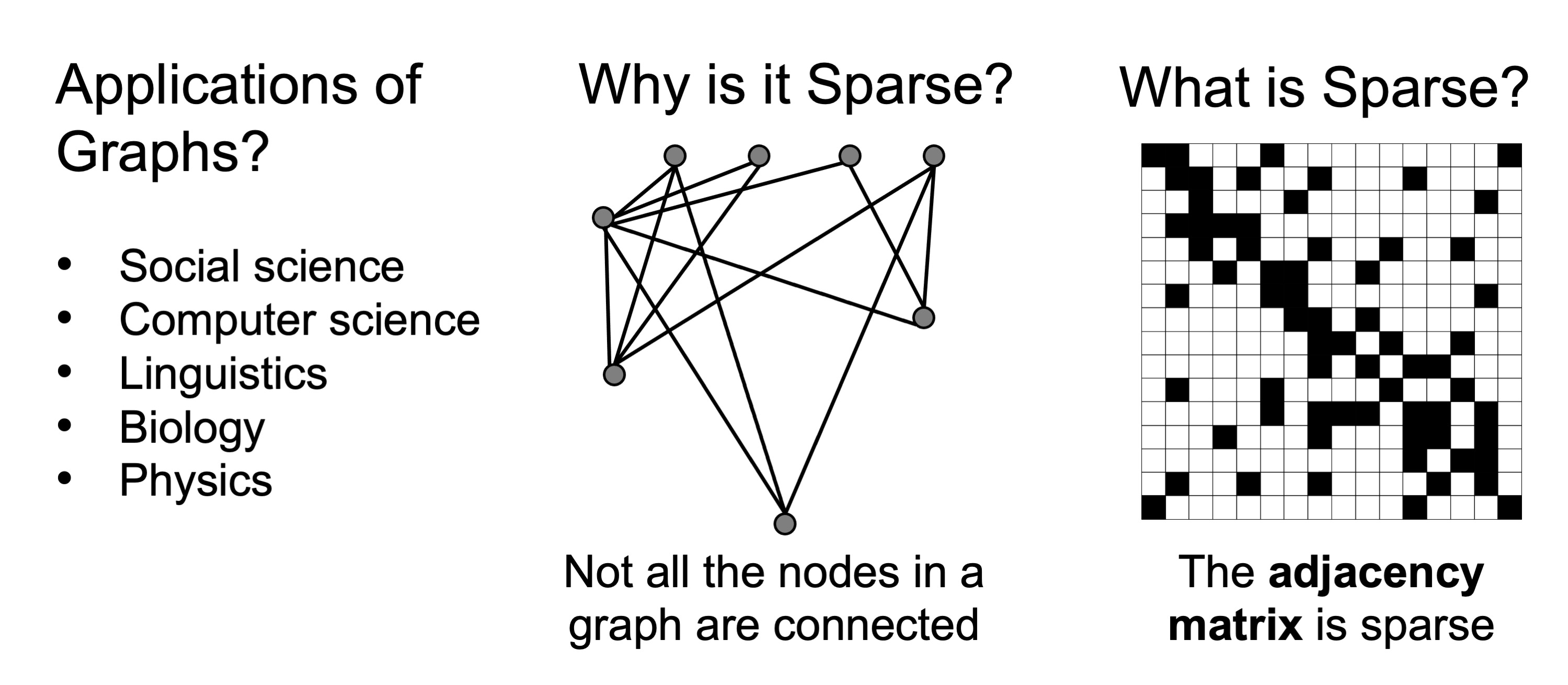
Graph analytics is another classic example of sparse problems that have several applications from social sciences to biology and physics. Since in a graph, not all the nodes are connected, the resulting adjacency matrix that represents the edges of the graph, is sparse. Since graphs are often very sparse, they are often extremely compressed.
Although compression allows efficient data storage and transfer, it can potentially create a computation bottleneck. This challenge is not only unsolved but also becomes more serious with the advent of DSAs. As they aggressively improve the performance of the main computation part that used to be the performance bottleneck, they may face the diminishing return suggested by Amdahl’s law: the main computation is now faster and data decompression is the bottleneck now. The performance implications of using compression along with DSAs have not been studied by prior work. To fill this gap of knowledge, we characterized the performance implications of compression formats used in sparse workloads (Copernicus) based on six key metrics, including memory bandwidth utilization, resource utilization, latency, throughput, power consumption, and balance ratio. Copernicus leads architects to knowingly choose the required sparse format and tailor their DSA for their target sparse applications, if necessary.
Improving compute utilization when running sparse matrices
Neural networks that are becoming more and more popular in many applications from image processing to financial problems are another example of sparse problems. Once we train a neural network, several weights get close-to-zero values. As a result, a common practice is to prune those small values because they do not impact the result. Therefore, the 2D matrix representation of the outcome neural network will be a sparse weight matrix.

Sparsity in neural networks may cause underutilization of computing units at hardware. Such a challenge occurs as a result of optimizing hardware just based on computation without considering what data requires. An example of such effort is accelerating the inference of neural networks using systolic arrays, the highly parallel arrays of computing units (e.g., multiplication and accumulation (MAC) units) for performing matrix multiplication. The dense structure of systolic arrays contradicts the sparse nature of neural network inference and leads to the underutilization of computation. To address this challenge, we proposed creating locally-dense neural networks for efficient inference on systolic arrays (Lodestar). Lodestar is a structured pruning approach that produces neural networks, the non-zero values of which are clustered spatially into locally dense regions that can be compactly stored in memory and efficiently streamed through systolic arrays. Lodestar consists of two key insights: (i) To capture the data reuse pattern in systolic arrays and enable data streaming, modifying the distribution of non-zero values is more influential than minimizing the number of operations or the memory footprint; and (ii) Examining the correlation among the filters rather than the individual filters increases the chances of creating a systolic-friendly neural network. To utilize Lodestar for streaming data from memory through systolic arrays, we proposed efficiently running the inference of CNNs using systolic arrays (Eridanus). Eridanus handles the timing and indexing of streaming dense blocks of data. The evaluations show that Lodestar and Eridanus run the inference of neural networks 8.4x faster than the state of the art. Although by utilizing the proposed techniques we can achieve the high throughput offered by the MAC-based systolic arrays, achieving low latency (not higher throughput) and scalability will still be key challenges. To resolve these challenges, we proposed multiplying matrices efficiently in a scalable systolic architecture (Meissa), which compared to state-of-the-art systolic arrays, offers 1.83x better single-batch inference latency by separating multipliers from the adders rather than combining them in a unified array of MACs.